Video Face Replacement
SIGGRAPH Asia, 2011
Abstract
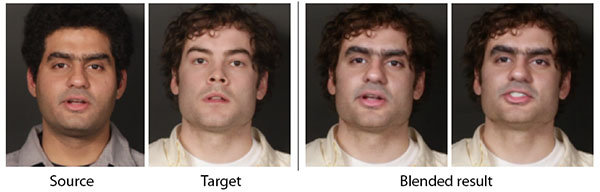
We present a method for replacing facial performances in video. Our approach accounts for differences in identity, visual appear- ance, speech, and timing between source and target videos. Unlike prior work, it does not require substantial manual operation or complex acquisition hardware, only single-camera video. We use a 3D multilinear model to track the facial performance in both videos. Using the corresponding 3D geometry, we warp the source to the target face and retime the source to match the target performance. We then compute an optimal seam through the video volume that maintains temporal consistency in the final composite. We showcase the use of our method on a variety of examples and present the result of a user study that suggests our results are difficult to distinguish from real video footage.
Download
Cite
BibtexThis work was supported in part by the NSF under Grant No. 0739255, NIH contract 1-R01-EY019292-01, and by a grant from the NTT-MIT Research Collaboration. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation.